LLM Quick Start
Setup
Option 1: Cloud
- Log in to https://workbench.posit.it/ and start a session in your IDE of choice
- We recommend RStudio for R, and Positron for R or Python
- Clone https://github.com/jcheng5/llm-quickstart
- Open
llm-quickstartas a Project (RStudio) or Folder (Positron) in your IDE - Grab your OpenAI/Anthropic API keys; see the thread in
#hackathon-22
Option 2: Local
Clone https://github.com/jcheng5/llm-quickstart
Grab your OpenAI/Anthropic API keys; see the thread in
#hackathon-22For R:
install.packages(c("ellmer", "shinychat", "dotenv", "shiny", "paws.common", "magick", "beepr"))For Python:
pip install -r requirements.txt
Introduction
Framing LLMs
- Our focus: Practical, actionable information
- Often, just enough knowledge so you know what to search for (or better yet, what to ask an LLM)
- We will treat LLMs as black boxes
- Don’t focus on how they work (yet)
- Leads to bad intuition about their capabilities
- Better to start with a highly empirical approach
Anatomy of a Conversation
LLM Conversations are HTTP Requests
- Each interaction is a separate HTTP API request
- The API server is entirely stateless (despite conversations being inherently stateful!)
Example Conversation
“What’s the capital of the moon?”
"There isn't one."
“Are you sure?”
"Yes, I am sure."
Example Request
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1",
"messages": [
{"role": "system", "content": "You are a terse assistant."},
{"role": "user", "content": "What is the capital of the moon?"}
]
}'- System prompt: behind-the-scenes instructions and information for the model
- User prompt: a question or statement for the model to respond to
Example Response (abridged)
Example Request
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1",
"messages": [
{"role": "system", "content": "You are a terse assistant."},
{"role": "user", "content": "What is the capital of the moon?"},
{"role": "assistant", "content": "The moon does not have a capital. It is not inhabited or governed."},
{"role": "user", "content": "Are you sure?"}
]
}'Example Response (abridged)
Tokens
- Fundamental units of information for LLMs
- Words, parts of words, or individual characters
- “hello” → 1 token
- “unconventional” → 3 tokens:
un|con|ventional - 4K video frame at full res → 6885 tokens
- Example with OpenAI Tokenizer
- Important for:
- Model input/output limits
- API pricing is usually by token (see comparison)
Choose a Package
- R:
ellmerhigh-level, easy, much less ambitious than langchain- OpenAI, Anthropic, Google are well supported
- Several other providers are supported but may not be as well tested
- Get help from Ellmer Assistant
- Python:
Your Turn
Instructions
Open and run one of these options:
01-basics.R- or
01-basics-bedrock.Rfor cloud
- or
01-basics-openai.py(low level library)01-basics-langchain.py(high level framework)01-basics-chatlas.py(high level framework, similar to R)- or
01-basics-chatlas-bedrock.pyfor cloud
- or
If it errors, now is the time to debug.
If it works, study the code and try to understand how it maps to the low-level HTTP descriptions we just went through.
Summary
- A message is an object with a
role(“system”, “user”, “assistant”) and acontentstring - A chat conversation is a growing list of messages
- The OpenAI chat API is a stateless HTTP endpoint: takes a list of messages as input, returns a new message as output
Creating chatbot UIs
Shiny for R
{shinychat} package
https://github.com/posit-dev/shinychat
- Designed to be used with ellmer
- Ellmer Assistant is quite good for getting started
Shiny for Python
Creating chatbots in Shiny for Python
- Shiny Assistant on the web can’t help you with
ui.Chatfor data privacy reasons, so instead…
Shiny Assistant for VS Code and Positron
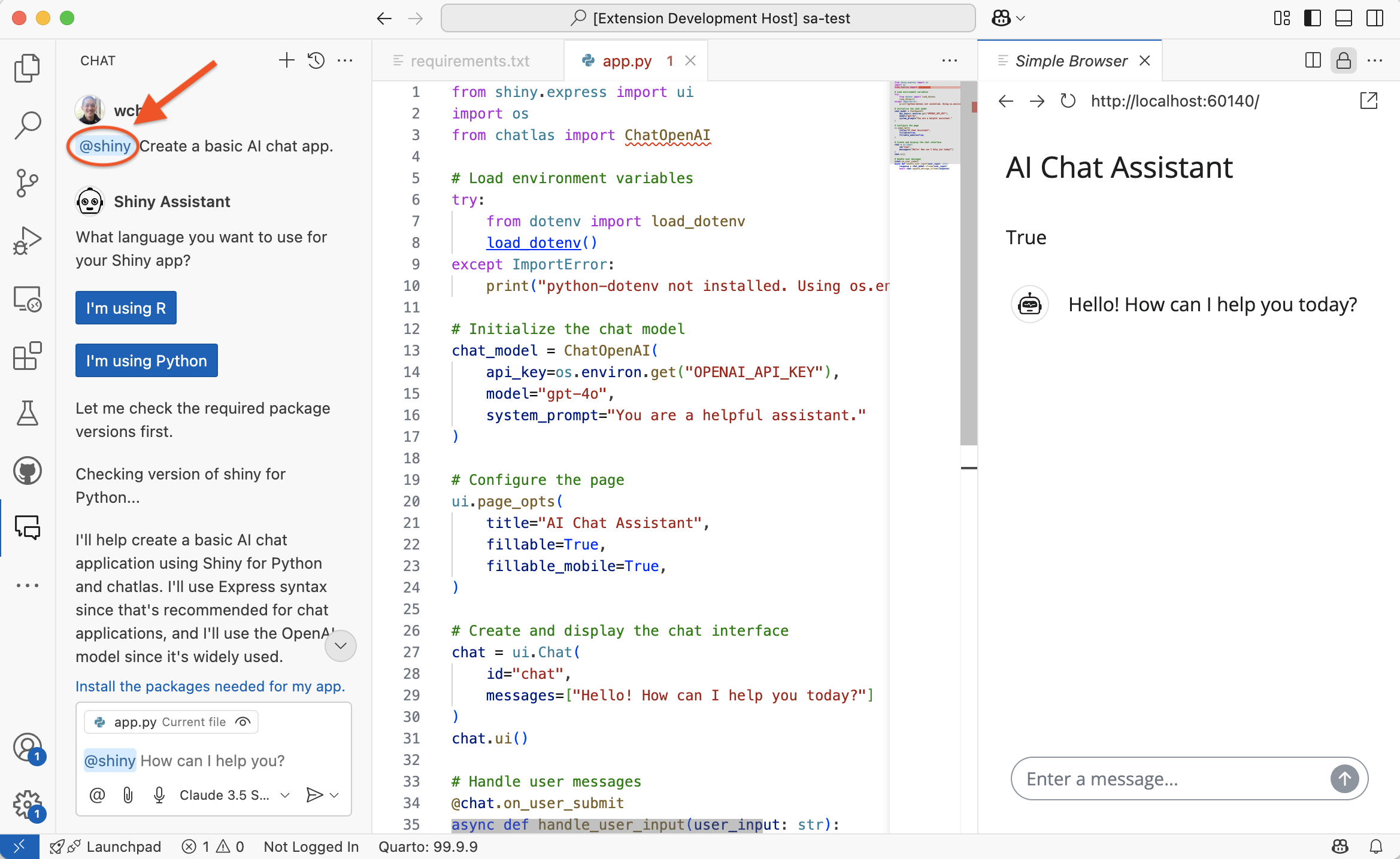
Installation
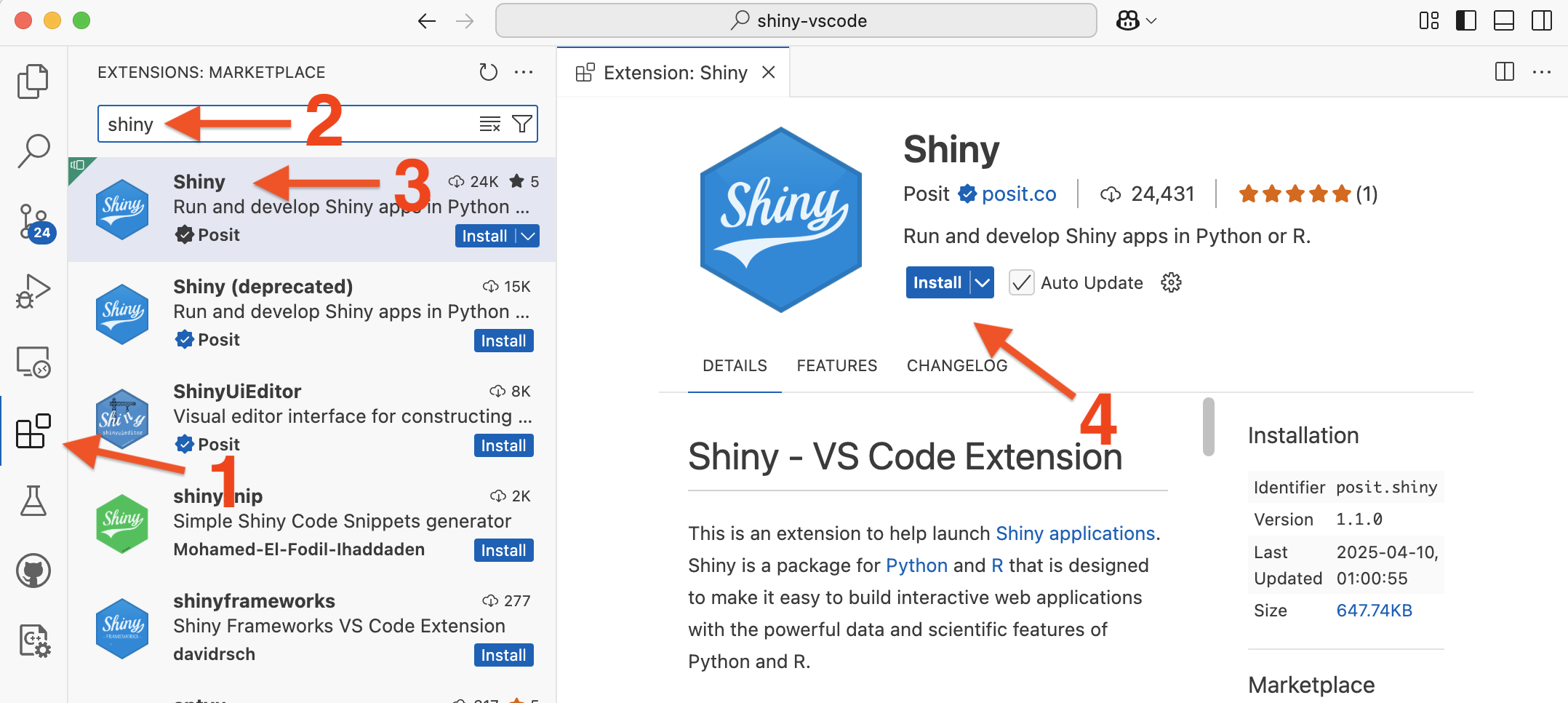
Shiny Assistant requirements
- In VS Code, requires Copilot subscription
- In Positron, requires:
- Anthropic or OpenAI API key
- Enable Positron Assistant. Instructions
{querychat}

https://github.com/posit-dev/querychat (R and Python)
Other Python frameworks
- Streamlit has an excellent chat component with a nice LangChain integration
- Gradio has a chat component that is extremely easy to use
Tool Calling
What is Tool Calling?
- Allows LLMs to interact with other systems
- Sounds complicated? It isn’t!
- Supported by most of the newest LLMs, but not all
How It Works
- Not like this - with the assistant executing stuff
- Yes like this
- User asks assistant a question; includes metadata for available tools
- Assistant asks the user to invoke a tool, passing its desired arguments
- User invokes the tool, and returns the output to the assistant
- Assistant incorporates the tool’s output as additional context for formulating a response
How It Works
Another way to think of it:
- The client can perform tasks that the assistant can’t do
- Tools put control into the hands of the assistant—it decides when to use them, and what arguments to pass in, and what to do with the results
- Having an “intelligent-ish” coordinator of tools is a surprisingly general, powerful capability!
Your Turn
Take a minute to look at one of the following docs. See if you can get them to run, and try to understand the code.
- R:
ellmerdocs (anticlimactically easy), or example02-tools.Rinllm-quickstartrepo - Python
openaiexample:02-tools-openai.py(tedious, low-level, but understandable)langchainexample:02-tools-langchain.py(not bad)chatlasexample:02-tools-chatlas.py(easy, likeellmer)
Model Context Protocol
- A standardized way for tools to make themselves available to LLM apps, without writing more code
- RPC protocol, so tools can be written in any language
- The application that uses the tool is an MCP client
- MCP Servers provide the tools. Examples:
- Google Maps
- Filesystem - access to files on disk
- Playwright MCP - control a web browser
- Clients use the tools. Examples: Claude Desktop app, Claude Code, Continue, Cursor, many others
Choosing a model
- OpenAI
- Anthropic Claude
- Google Gemini
- Open weights models (can run locally)
OpenAI models
- GPT-4.1: good general purpose model, 1 million token context length
- GPT-4.1-mini and GPT-4.1-nano are faster, cheaper, and dumber versions
- o3: reasoning model; better for complex math and coding, but much slower
and more expensive - o4-mini: faster and cheaper reasoning model, not as good as o3 but cheaper than GPT-4.1
- API access via OpenAI or Azure
- Takeaway: Good models for general purpose use
- All OpenAI models
Anthropic models
- Claude Sonnet 4: good general purpose model, best for code generation. Has thinking mode.
- Claude Sonnet 3.7 and 3.5 are both still excellent
- Claude Opus 4: even stronger than Sonnet 4 (supposedly), but more expensive and slower. Has thinking mode.
- Claude Haiku 3.5: Faster, cheaper, but not cheap enough
- API access via Anthropic or AWS Bedrock (instructions for using Bedrock at Posit)
- Takeaway: Best model for code generation
- All Anthropic models
Google models
- Gemini 2.5 Pro: 1 million token context length. Has thinking mode.
- Gemini 2.5 Flash: 1 million token context length, very fast. Has thinking mode.
- Takeaway: Competitive with OpenAI and Anthropic
- All Gemini models
Llama models
- Open weights: you can download the model
- Can run locally, for example with Ollama
- Llama 3.1 405b: text, 229GB. Not quite as smart as best closed models.
- Llama 3.2 90b: text+vision, 55GB
- Llama 3.2 11b: text+vision, 7.9GB (can run comfortably on Macbook)
- API access via OpenRouter, Groq, AWS Bedrock, others
- Takeaway: OK models if you want to keep all information on premises.
Other open weights model families
- 🇺🇸 Gemma 3 (Google)
- 🇨🇳 Qwen3 (Alibaba)
- 🇨🇳 DeepSeek R1
- 🇫🇷 Mistral 3.2 Small
- 🇨🇳 Kimi K2 (MoonshotAI)
- 🇨🇳 GLM-4.5 Air (Z.ai)
Customizing behavior and knowledge
- You want to customize how the LLM responds
- LLM doesn’t know your specific information
Some solutions
- Prompt engineering
- Retrieval-Augmented Generation
- Agentic search
- Fine tuning
Prompt engineering: Directing behavior
- “Respond with just the minimal information necessary.”
- “Think through this step-by-step.”
- “If the user asks a data-related question, produce R code to accomplish that task.”
- “Only provide answers that you are sure about. If you are uncertain about an answer, say so.”
Prompt engineering: Using examples to guide behavior
Goal: Extract ingredient list from recipe and return in a structured format.
Example user input:
In a large bowl, cream together 1 cup of softened unsalted butter and ½ cup of white sugar until smooth. Beat in 1 egg and 1 teaspoon of vanilla extract. Gradually stir in 2 cups of all-purpose flour until the dough forms. Finally, fold in 1 cup of semisweet chocolate chips. Drop spoonfuls of dough onto an ungreased baking sheet and bake at 350°F (175°C) for 10-12 minutes, or until the edges are lightly browned. Let the cookies cool on the baking sheet for a few minutes before transferring to a wire rack to cool completely. Enjoy!
System prompt 1: just instructions
The user input contains a recipe. Extract a list of ingredients and return it in JSON format.Assistant response:
System prompt 2: detailed description of output
The user input contains a recipe. Extract a list of ingredients and return it in JSON format. It should be an array of objects, where each object has keys `ingredient`, `quantity`, and `unit`. Put each object on one line of output.Assistant response:
[
{"ingredient": "unsalted butter", "quantity": 1, "unit": "cup"},
{"ingredient": "white sugar", "quantity": 1/2, "unit": "cup"},
{"ingredient": "egg", "quantity": 1, "unit": "large"},
{"ingredient": "vanilla extract", "quantity": 1, "unit": "teaspoon"},
{"ingredient": "all-purpose flour", "quantity": 2, "unit": "cups"},
{"ingredient": "semisweet chocolate chips", "quantity": 1, "unit": "cup"}
]System prompt 3: one-shot example
The user input contains a recipe. Extract a list of ingredients and return it in JSON format.
Example Output:
```json
[
{ "ingredient": "Flour", "quantity": 1, "unit": "cup" },
{ "ingredient": "Vegetable oil", "quantity": 0.5, "unit": "tsp" },
{ "ingredient": "Onion", "quantity": 1, "unit": null },
]
```Assistant response:
[
{ "ingredient": "Unsalted butter", "quantity": 1, "unit": "cup" },
{ "ingredient": "White sugar", "quantity": 0.5, "unit": "cup" },
{ "ingredient": "Egg", "quantity": 1, "unit": null },
{ "ingredient": "Vanilla extract", "quantity": 1, "unit": "teaspoon" },
{ "ingredient": "All-purpose flour", "quantity": 2, "unit": "cups" },
{ "ingredient": "Semisweet chocolate chips", "quantity": 1, "unit": "cup" }
]Adding context/knowledge to prompt
- Add documentation files to prompt
- Examples
- Ellmer assistant uses README files in prompt
- Querychat
- FastHTML LLM prompt
- Docs must fit in context window
- Add positive examples (negative examples don’t work well)
RAG: Retrieval Augmented Generation
- Useful when documents don’t fit into context window
- Steps:
- User sends query to app: “How do I …?”
- App retrieves relevant chunks of text via search
- App sends text and query to LLM
- <chunk 1>, <chunk 2>, <chunk 3>. How do I …?
- LLM responds with answer
- Search method typically a semantic instead of keyword search, using vector DB
- LLM will only know about chunks that were retrieved; does not “know” entire corpus
- In general, prompt stuffing works better, if docs fit in context window
Agentic search
- Similar to RAG:
- Extra information is provided to LLM
- Different from RAG:
- Application does not search documents and send to LLM along with user prompt
- User prompt is sent to LLM, then LLM uses a tool to search for relevant documents
Fine tuning
- Update weights for an existing model with new information
- Not all models can be fine-tuned
- Data must be provided in chat conversation format, with query and response
- Can’t just feed it documents – this makes fine-tuning more difficult in practice
- Supposedly not very effective unless you have a lot of training data
Takeaways
- First try prompting, then RAG or agentic search, and then fine tuning.
- Other resources
- OpenAI’s prompt engineering guide
- Anthropic’s prompt engineering guide
- Fine-tuning vs. RAG article
Getting structured output
Going beyond chat
- Structured output can be easily consumed by code: JSON, YAML, CSV, etc.
- Unstructured output cannot: text, images, etc.
LLMs are good at generating unstructured output, but with a little effort, you can get structured output as well.
Several techniques (choose one)
- Post-processing: Use a regular expression to extract structured data from the unstructured output (e.g.
/```json\n(.*?)\n```/) - System prompt: Simply ask the LLM to output structured data. Be clear about what specific format you want, and provide examples—it really helps!
- Structured Output: GPT-4.1 and GPT-4.1-mini have a first-class Structured Output feature: outputs strictly adhere to a JSON schema you write. (Docs: openai, LangChain)
- Tool calling: Create a tool to receive your output, e.g.,
set_result(object), where its implementation sets some variable. (Works great for ellmer.) - LangChain: Has its own abstractions for parsing unstructured output
Ask #hackathon-22 for help if you’re stuck! (Or ask ChatGPT/Claude to make an example.)
Vision
Using images as input
- Modern models are pretty good at this—but this frontier is especially jagged
- Can understand both photographs and plots
- Examples for R and Chatlas are in your repo as
05-vision* - See docs for LangChain multimodal, OpenAI vision